Our Concept Analytics Lab (CAL) team LOVES concepts. In our daily work, we keep seeing the value of the concept-based view of language in bringing insight to thinking, attitudes, and behaviours of people. But how important is the concept-based research for a wider linguistic community? Can concept-based research impact other disciplines and industries? Can you commercialise your concept-based knowledge?

With the aim of consolidating research and application of concept-based approaches to text analysis we gathered experts in the field for the first Concept Quest conference.
The event Concept Quest: Navigating Ideas on and Through Linguistic Concepts took place in March 20204 at the University of Sussex. It focussed on the work of CAL and other researchers from a range of academic disciplines. We hosted talks and panels from scholars studying everything from AI concepts to the impact of trade deals on the economy and commercialising concepts in the process of wine production.
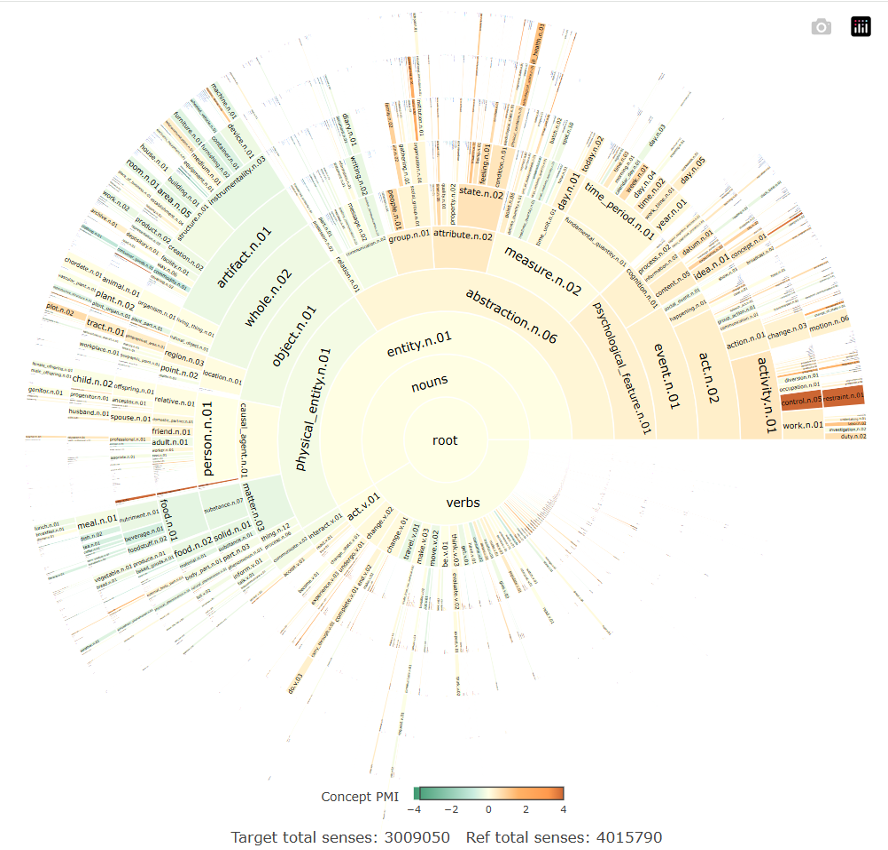
Justyna Robinson, the Director of the Concept Analytics Lab, started by talking about the aims and advantages of concept mining as a methodology. Concepts are not encapsulated by a single word but are be observable by a set of words, phrases and/or constructions. This allows us to understand how individual terms might be used differently over time, and how they may come to represent different concepts. CAL’s researcher Rhys Sandow then discussed how one can visualise conceptual ontologies and showed how one can turn complex sets of lexical relations into clear diagrammatic representations. Such representations can shed light on conceptual, including socio-conceptual, differences that are inaccessible to more traditional approaches to the analysis of large texts.

Following this, Louise Sylvester (Westminster) talked about how concepts can be incorporated into studies of Medieval English. Her work focuses on the adoption of terms from French into English during this period, and through the use of a semantic hierarchy, she is able to inspect in which cases French pushed out the English variant, and in which cases this did not occur. The use of concepts allows us to see the patterns that emerge in synonym relationships, even from long ago.
Haim Dubossarsky (QMUL) approached the study of concepts from a computational angle, discussing the ways in which we currently carry out computational and corpus linguistics, such as collocations, and how we can improve on these methods. Through the projection of a word’s usage onto a series of vectors, one is able to map the meanings of the word and their change over time. This technique provides a computational boost to the analysis of meaning and represents an important link between the world of linguistics and that of computer science that the Concept Analytics Lab covets.
The talks on theoretical and methodological aspects of doing concept research were complemented by talks addressing applications of concepts in archival work and in commercial endeavours.
Piotr Nagórka (Warsaw’s Cultural Terminology Lab) discussed the exploration of communications systems and terminological sciences. He probed how the terminology we use to refer to types of wine maps onto production process itself. In this case, for wine. His work shows how one might commercialise concept research by marrying the study of concepts with processes and techniques within the manufacturing sciences.

Angela Bachini and Kirsty Patrick, who work on the Mass Observation project helped us understand how archivists arrive at identifying important concepts in indexing of a new text. We learned a great deal from the Mass Observation team about their workflow and how we as researchers can best help archivist to automate indexing via key-concept detection.

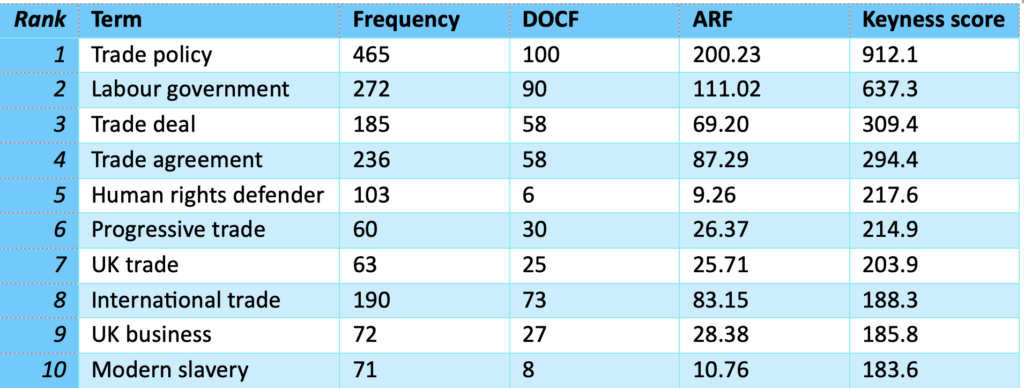
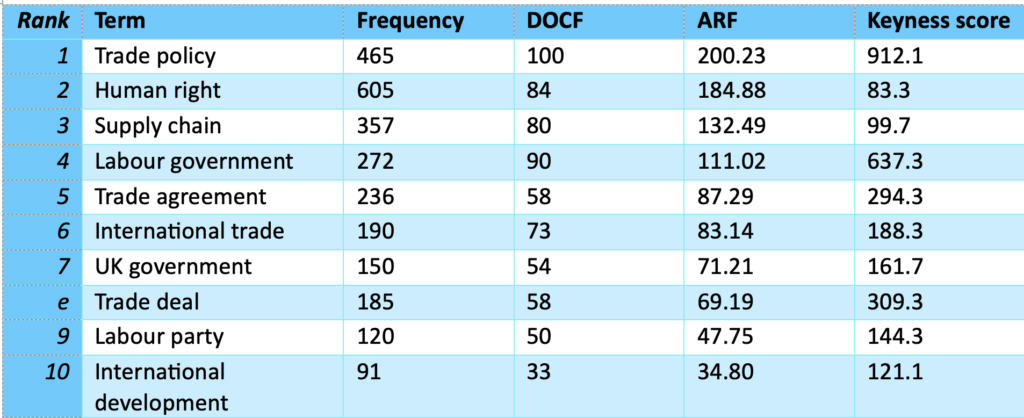
The event finished with a panel discussion on why concepts matter led by Lynne Murphy (Sussex), in which Piotr Nagorka, Kirsty Pattrick, were joined by Julie Weeds (Sussex AI) and Alan Winters (Sussex, CITP). Alan reflected on the value of concepts in trade analysis, particularly to understand the trade-offs that people are willing to make with regard to global trade. These kind of complex attitudes are difficult to access with other methods, particularly the quantitative methods often used in economics. The advantage of concept analysis, where participants can describe their accounts in rich detail which can then be computationally analysed, is clear in this case. Louise Sylvester added that in her work on Medieval English, concepts help us understand how people living in that era made sense of the world and what categories were meaningful for them. This helps greatly with noticing patterns of use in historical linguistics, and also helps us to understand how the concept of something like a farm has changed from the middle ages to the present day.
We continued chatting over some delicious wine (thanks to a generous sponsorship from Mass Observation) and made new connections across institutions and fields. This is exactly the kind of result we envisage from a successful colloquium, and we were proud to have hosted such a stimulating day. Our gratitude extends to all the wonderful speakers and attendees for making this event so brilliant!
To conclude our reflections, the Concept Quest highlighted the value of concept-based and concept-led research and applications. Researching concepts matters for theory of language and knowledge representation as we consider conceptual hierarchies, lexicalised and non-lexicalised concepts, and emergence of new concepts/ideas. At a methodological level, concepts pose a challenge for traditional word-based corpus and NLP techniques. Therefore, new ways of extracting conceptual information from big data is needed. At a more applied level, empirical ways of gaining access to conceptual information are invaluable for other sectors and disciplines which use large text data. Thus, strengthening objectivity and replicability of concept research will open up this research for other sectors which seek more expert analyses. That development can also lead to impactful research and even commercialisation of conceptual research.
Please get in touch here to find out which key concepts and themes are revealed in your data.