by Rhys Sandow and Justyna Robinson
Surveys which collect responses to open questions are a popular and valuable way of gauging peoples’ attitudes. But they also present specific challenges for keyness analysis in corpus linguistics as the results can be misleading. For example, a high frequency of term X may be skewed by one or two documents within the corpus, rather than being representative of attitudes among the survey respondents more broadly. In such cases, traditional corpus linguistic measures of difference, such as relative frequencies or keyness are not appropriate. In such cases, we advocate for the use of measures of dispersion across a corpus, such as Average Reduced Frequency (ARF) and Document Frequency (DOCF). This distinction between frequency and dispersion is critical to develop meaningful insights into large data sets, particularly in the context of policy consultation where an understanding of plurality and consensus is highly important.

Let us demonstrate how to solve this problem on the basis of examples from data we recently analysed. Concept Analytics Lab (CAL) was tasked by the UK Trade Policy Observatory (UKTPO) to analyse responses to the Labour Party’s Trade Policy Forum in the build-up to the Labour Party’s annual conference in October 2023. The survey gathered 302 answers to seven questions comprising c. 250,000 words of data. Many of the submissions came from groups with very particular interests, such as specific industries or specific local communities. Therefore, some responses contained detailed discussions of issues critically important to the submitter, but not necessarily widespread among all respondents. For example, when running a keyword analysis, the eighth most key word (with the ententen21 corpus as our baseline) was gpi (genuine progress indicator) with 35 hits across the corpus. However, upon closer inspection, these hits are spread across only 2 of the 302 responses. Thus, while gpi has a high keyness score, it cannot be said that it is a salient topic across the corpus as its use is so highly concentrated across 0.66% of documents.
In order to remedy this limitation of keyness analysis, we considered the spread of terms across the corpus using Sketch Engine’s Average Reduced Frequency (ARF) statistic. ARF is a modified frequency measure that prevents results being skewed by a specific part, or a small number of parts, of a corpus (for more detail on the mathematics behind the measure, see here). Where the ARF and absolute frequency are similar, this suggests a relatively even distribution of a given term across a corpus. However, when there are large discrepancies between the absolute frequency and ARF, this is indicative of a skew towards a small subset of the corpus. For example, while the absolute frequency of gpi in the corpus is 35, the ARF is 2.7 (DOCF, 2), highlighting its lack of dispersion. Similarly, the term gender-just has an absolute frequency of 19 but an ARF of 1.32 (DOCF, 1), highlighting that this term is not characteristic of the data set as a whole, but is highly salient within a small subset of the corpus. By contrast, labour, with an absolute frequency of 1, 434 had an ARF of 725.74 (DOCF, 226), highlighting its spread across the corpus.
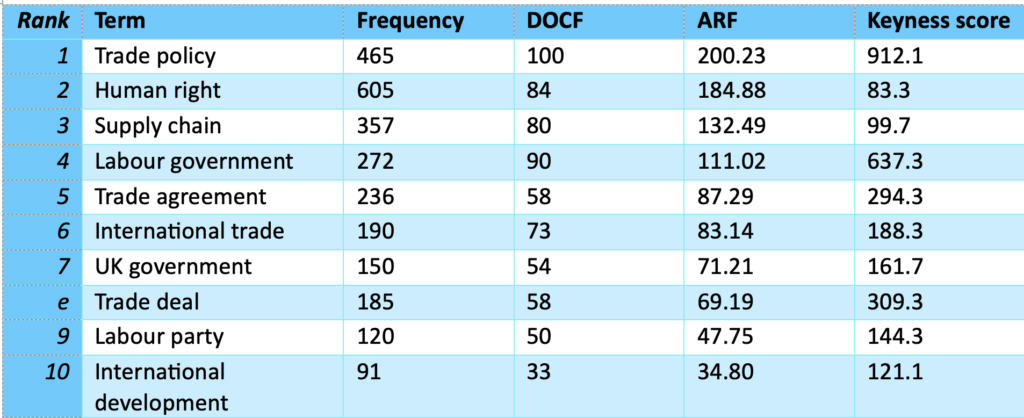
When analysing corpus data, methodological decisions can have highly impactful repercussions for the analysis. For example, let’s take the top 10 key multi-word terms from the Labour Party Policy Forum data set ordered by keyness score (see Table 1) and compare it with the top 10 multi-word terms ordered by the highest ARF statistic (see Table 2).
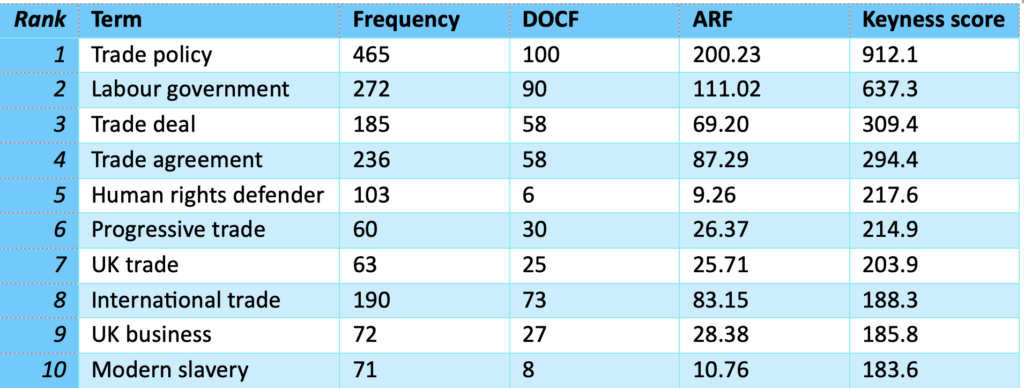
This analysis highlights, in particular, two obvious outliers, namely ‘human rights defender’ and ‘modern slavery’. The low DOCF and ARF scores highlight that they are highly concentrated within a small number of submissions and, so, are not characteristic of the data set more broadly.
While no multi-word term occurs in the majority of documents, table 2 provides a perspective on the most broadly dispersed multi-word terms. It is important to note the substantial overlap between the two measurements in tables 1 and 2, e.g. ‘trade policy’, ‘trade deal’, ‘trade agreement’, ‘international trade’, and ‘labour government’, appear in both. However, the advantage of the ARF ordered data is that there are no clear outliers, skewed by individual, or a very small number of, responses. This means that it is the second data which provides a more valid overview of the content of the data set.
Using a traditional approach to keyness analysis, conclusions may recommend interventions around trade and human rights defenders or modern slavery. However, an analysis of ARF highlights that this is misleading and does not get to the essence of the data set. What is more, policy recommendations based on the former statistic only may result in the disproportionate influence of those who lobby in relation to very specific terms at the expense of more widespread priorities and concerns.
This ARF analysis formed part of our analysis of the 2023 Labour Party’s Policy Forum that we conducted for the UKTPO, which can be accessed here.
Labour Policy Forum (2023). National Policy Forum Consultation 2023. Britain in the World..
Gasiorek, M and Justyna Robinson. (2023) What can be learnt from the Labour Party’s consultation on Trade? UKPTO Blog.
We identify conceptual patterns and change in human thought through a combination of distant text reading and corpus linguistics techniques.
Sussex Digital Humanities Lab
University of Sussex
Silverstone SB211
Arts Road, Falmer,
East Sussex, BN1 9RG