Concept Analytics Lab delivers corpus methods training package for SEDarc

Concept Analytics Lab (CAL) recently delivered a series of six training workshops for the South East Doctoral Training Arc (SEDarc), a UKRI (ESRC) funded Doctoral Training Partnership supporting doctoral researchers in the social sciences. The sessions introduced SEDarc research students to corpus linguistics and demonstrated the practical value of corpus tools, including CAL’s own ConceptCruncher, for social science research, particularly where it intersects with policy.
The training introduced SEDarc researchers to the following topics:
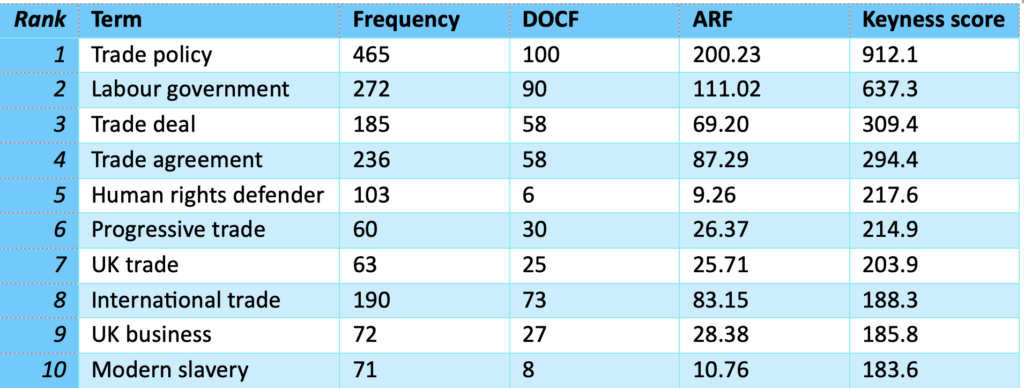
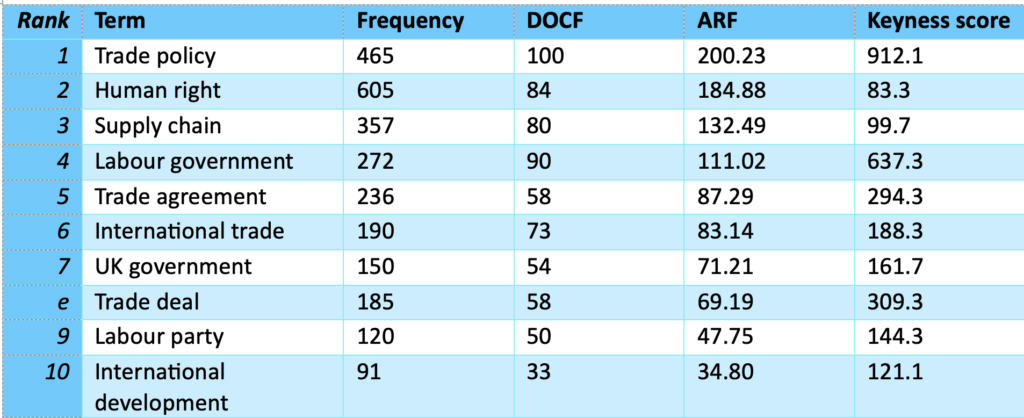
- Quantitative corpus analysis, including raw and relative frequencies, wordlists, reference corpora, and keyword extraction.
- Collocation analysis, including window-based and grammar-based approaches, and interpretation of collocation statistics and visualisations.
- Qualitative corpus methods, including close reading via concordances and the use of annotation to support interpretation.
- Affective (e.g. positive, neutral, negative sentiment) and thematic annotation.
- Comparative corpus analysis across words and social, temporal, or spatial clusters of data.
- Building custom corpora, including data selection, preparation, metadata design, compilation, and creation of sub-corpora
- Best practice in selecting and using reference corpora for benchmarking and keyword analysis
- Planning and structuring corpus analyses using top-down and bottom-up strategies
- Applications of corpus methods in academic research, policy-making, and commercial contexts
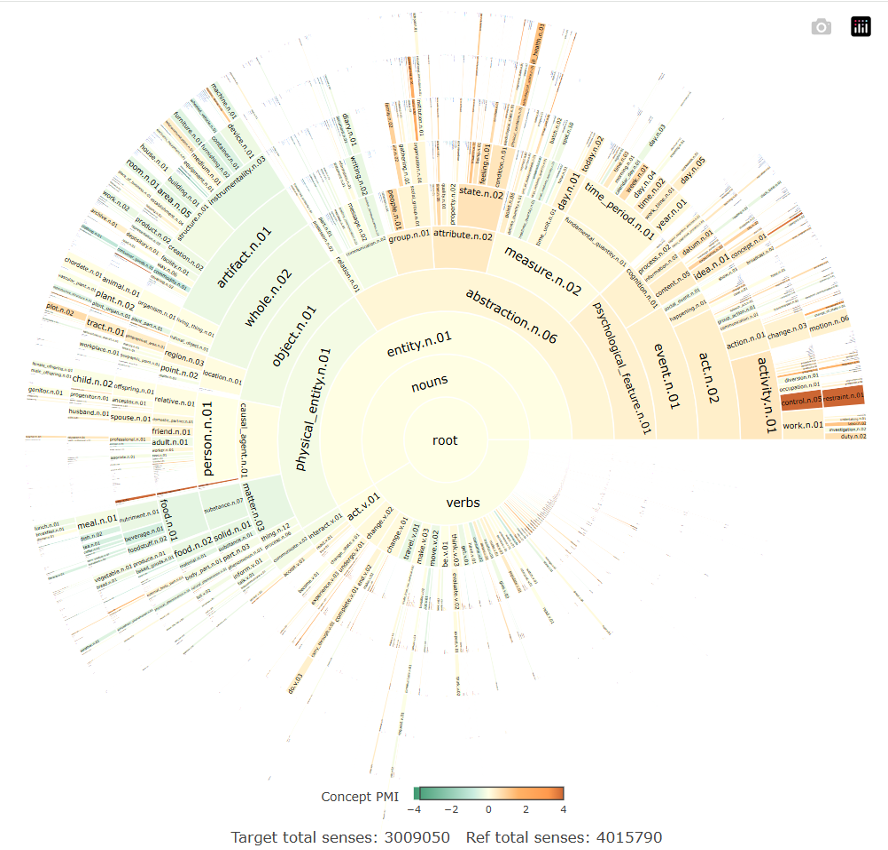
- An introduction to next-generation tools in corpus linguistics that focus on the extract of meaning from texts, namely the ConceptCruncher, developed by the Concept Analytical Lab at the University of Sussex.
If you would like to discuss the possibility of CAL providing bespoke training on corpus and computational linguistic methods for your organisation, please contact Justyna.Robinson@sussex.ac.uk
About Us
We identify conceptual patterns and change in human thought through a combination of distant text reading and corpus linguistics techniques.