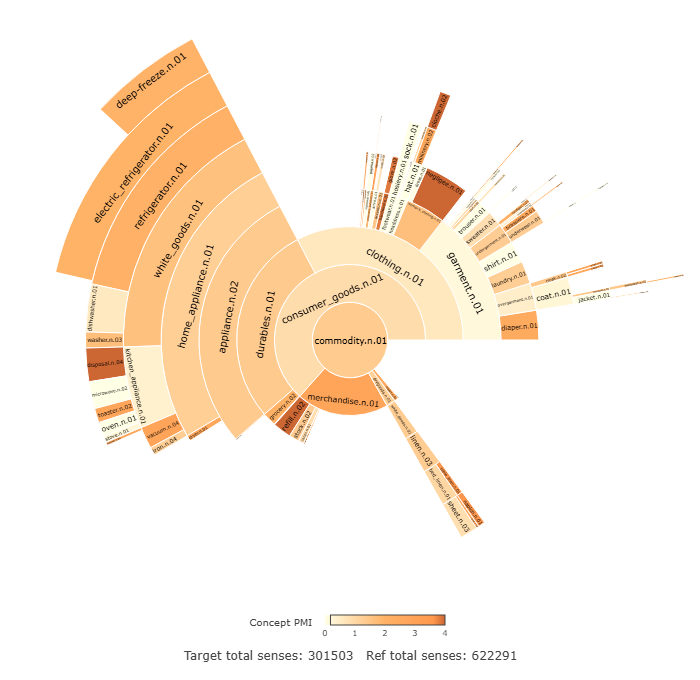
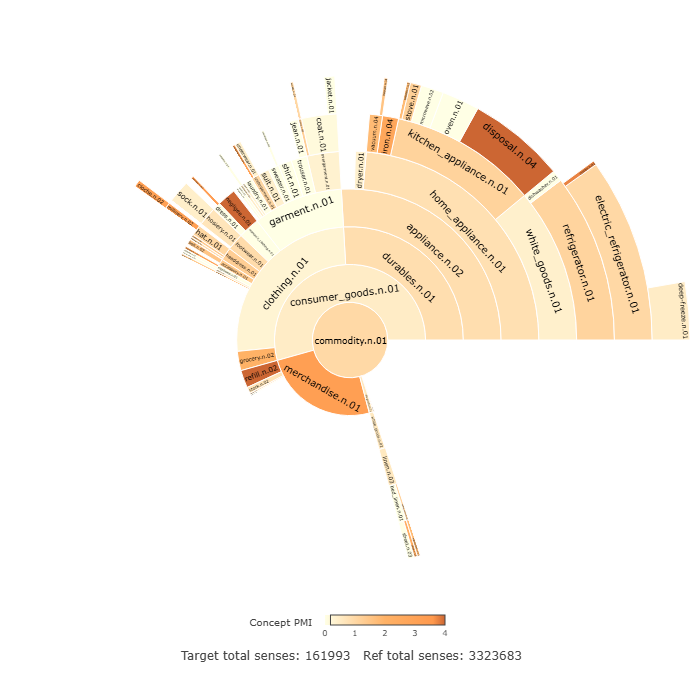
Alexander, Marc. 2018. Lexicalization Pressure. Plenary lecture delivered at 20th International Conference on English Historical Linguistics, University of Edinburgh.
Baker, Paul. 2004. Querying keywords: Questions of difference, frequency, and sense in keyword analysis. Journal of English Linguistics, 32: 346-59.
Bianchi, Suzanne M., Liana C. Sayer, Melissa A. Milkie, & John P. Robinson. 2012. Housework: Who did, does or will do it, and how much does it matter? Social Forces, 91: 55-63.
Bucholtz, Mary. 2012. Word Up: Social meanings of slang in California youth culture. In Leila Monaghan, Jane E. Goodman, & Jennifer Meta Robinson (eds.), A Cultural Approach to Interpersonal Communication: Essential Readings, 2nd ed, 274-97. Chichester: Wiley.
Dallachy, Fraser. 2024. A human-scale set of categories for the Historical Thesaurus of English. Dictionaries, 45: 145-68.
Eckert, Penelope. & Sally McConnell-Ginet. 2013. Language and Gender, 2nd edition. Cambridge: Cambridge University Press.
Fellbaum, Christiane (ed.). 1998. WordNet: An Electronic Lexical Database. Cambridge, MA: MIT Press.
Fitzmaurice, Susan. & Seth Mehl. 2022. Volatile concepts: Analysing discursive change through underspecification in co-occurrence quads. International Journal of Corpus Linguistics, 27: 428-50.
Fitzmaurice, Susan., Justyna A. Robinson, Marc Alexander, Iona C. Hine, Seth Mehl, & Fraser Dallachy. 2017. Linguistic DNA: Investigating conceptual change in Early Modern English Discourse. Studia Neophilologica, 89: 21–38.
Grondelaers, Stefan. & Dirk Geeraerts. 2003. Towards a pragmatic model of cognitive onomasiology. In Hubert Cuyckens , René Dirven and John R. Taylor (eds.), Cognitive Approaches to Lexical Semantics, 67-92. Berlin: Mouton.
Hoang, Hung H., Su N. Kim, and Min-Yen Kan. 2009. A re-examination of lexical association measures. In Proceedings of the Workshop on Multiword Expressions: Identification, Interpretation, Disambiguation and Applications, 31-9.
Kay, Christian., Marc Alexander, Fraser Dallachy, Jane Roberts, Michael Samuels, and Irené Wotherspoon (eds). 2023. The Historical Thesaurus of English (2nd edn., version 5.0). University of Glasgow. https://ht.ac.uk/. Accessed September 11, 2024.
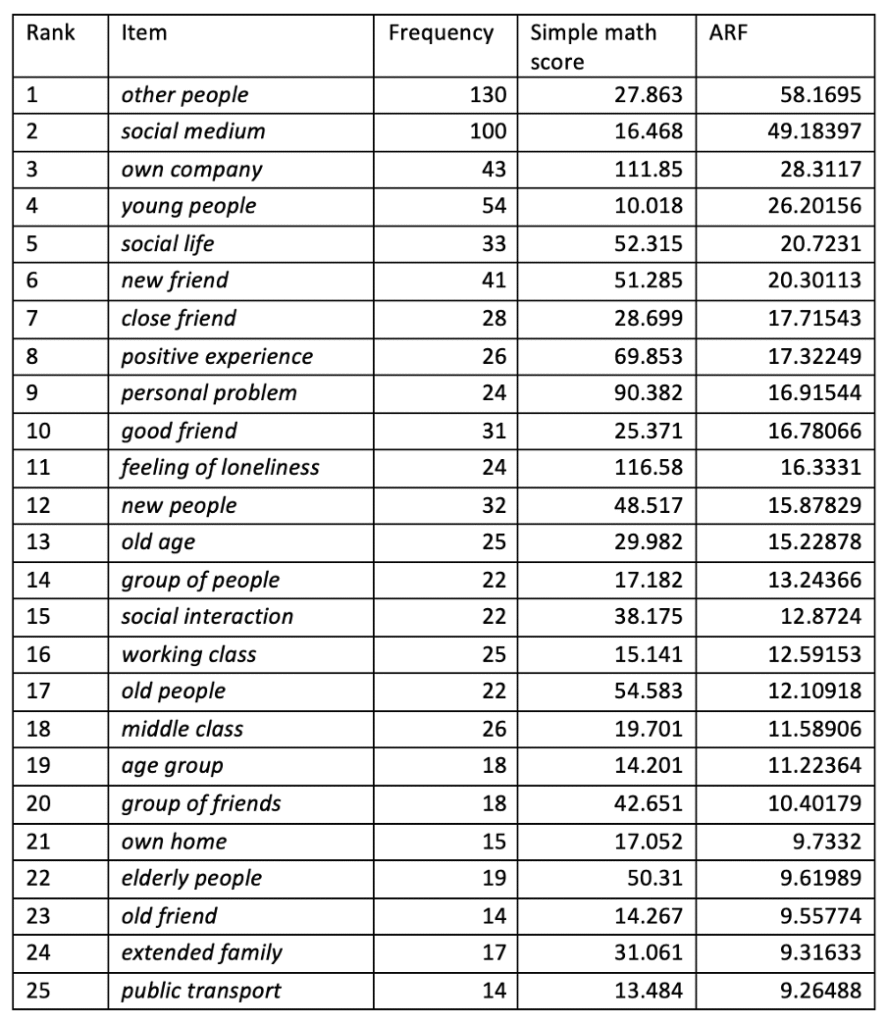
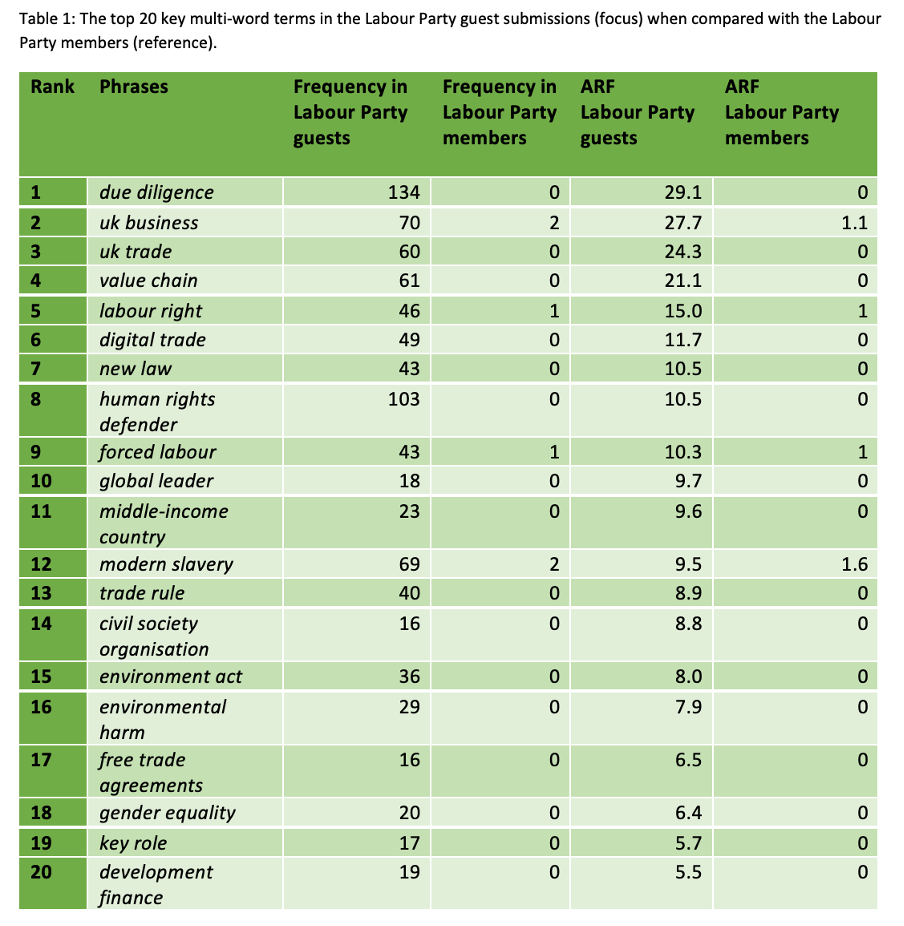
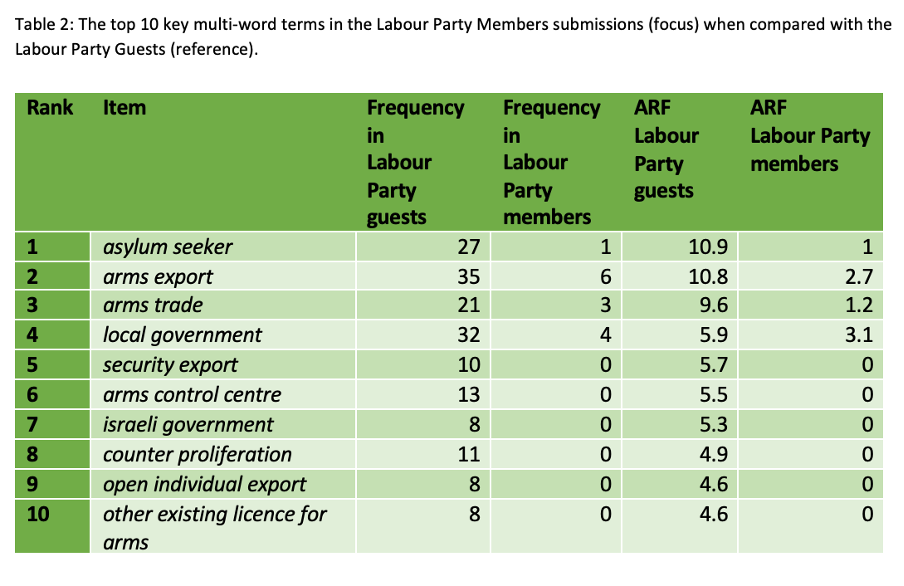
Kilgrarriff, Adam. 2009. Simple maths for keywords. In Michaela Mahlberg, Victorina González-Díaz, & Catherine Smith (eds.), Proceedings of the Corpus Linguistics Conference CL2009. Available at: https://www.sketchengine.eu/wp-content/uploads/2015/04/2009-Simple-maths-for-keywords.pdf. Accessed 18 July 2024.
Lakoff, Robin. 1973. Language and woman’s place. Language in Society, 2 (1), 45-80.
Mass Observation. 2010. Mass Observation Archive. Available online at: http://www.massobs.org.uk/. Accessed August 21, 2024.
Mehl, Seth. 2022. Discursive Quads: New Kinds of Lexical Co‐occurrence Data With Linguistic Concept Modelling. Transactions of the Philological Society, 120 (3), 474-88.
Mohamed, Muhidin. & M. Oussalah. 2014. A comparative study of conversion aided methods for WordNet sentence textual similarity. Proceedings of the AHA! Workshop on Information Discovery in Text, 37-42.
Murphy, Lynne M. 2010. Lexical Meaning. Cambridge: Cambridge University Press.
Newman, Matthew L., Carla J. Groom., Lori D. Handelman., & James W. Pennebaker. 2008. Gender differences in language use: An analysis of 14,000 text samples. Discourse Processes, 45: 211–36.
Papandrea, Simone., Alessandro Raganato, and Claudio D. Bovi. 2017. “SupWSD: a flexible toolkit for supervised word sense disambiguation,” in Proceedings of the 2017 EMNLP System Demonstrations, 103-8.
Piao, Scott., Fraser Dallachy, Alistair Brown, Jane Demmen, Steve Wattam, Phillip Durkin, James McCracken, Paul Rayson, & Marc Alexander. 2017. A time-sensitive historical thesaurus-based semantic tagger for deep semantic annotation. Computer Speech & Language, 46: 113–35.
Princeton University. 2010. About WordNet. Available at: https://wordnet.princeton.edu/. Accessed 10/12/2024.
Pütz, Martin, Reif, Monika, and Justyna A. Robinson (eds.). 2014. Cognitive Sociolinguistics. Amsterdam: John Benjamins.
Robinson, Justyna A. 2010. Awesome insights into semantic variation. In Dirk Geeraerts, Gitte Kristiansen, & Yves Piersman (eds.), Advances in Cognitive Sociolinguistics, 85-109. Berlin: Mouton de Gruyter.
Robinson, Justyna A. 2012. A gay paper: Why should sociolinguistics bother with semantics? English Today, 28: 38-54.
Robinson, Justyna A. & Julie Weeds. 2022. Cognitive sociolinguistic variation in the Old Bailey Voices Corpus: The case for a new concept-led framework. Transactions of the Philological Society, 120, 399-426.
Robinson, Justyna A., Rhys J. Sandow, & Roberta Piazza. 2023. Introducing the keyconcept approach to the analysis of language: The case of regulation in Covid-19 diaries. Frontiers in Artificial Intelligence, 6, doi: https://doi.org/10.3389/frai.2023.1176283.
Sylvester, Louise., Imogen Marcus, & Richard Ingham. 2017. A bilingual thesaurus of everyday life in Medieval England: Some issues at the interface of semantics and lexicography. International Journal of Lexicography, 30: 309–21.
Sylvester, Louise., Megan Tiddeman, and Richard Ingham. 2020. An analysis of French borrowings at the hypernymic and hyponymic levels of Middle English. Lexis: Journal of English Lexicography, 16, doi: 10.4000/lexis.4841.
Sylvester, Louise, Megan Tiddeman, and Richard Ingham. 2022. Semantic Shift in Middle English: Farming and Trade as Test Cases. Transactions of the Philological Society, 120: 427–46.
Sylvester, Louise and Megan Tiddeman. 2024. Lexicalization, polysemy and loanwords in anger: A comparison with non-affective domains in Middle English”, Lexis 3, doi: https://doi.org/10.4000/12ize
Thaler, Richard H. and, Sunstein Cass R. 2008. Nudge: Improving Decisions About Health, Wealth, and Happiness. New Haven: Yale University Press.
Thébaud, Sarah., Sabino Kornrich, & Leah Ruppanner. 2021. Good housekeeping, great expectations: Gender and housework norms. Sociological Methods & Research, 50: 1186-214.
Trousdale, Graeme. 2008. Constructions in grammaticalization and lexicalization: Evidence from the history of a composite predicate construction in English. In Graeme Trousdale & Nikolas Gisborne (eds.), Constructional Approaches to English Grammar, 33-67. Berlin: Mouton.
Vogelsanger, Johanna. 2024. Obsolescence and innovation in the Middle English religious lexicon. To appear in Transactions of the Philological Society. Advance Online Publication, https://doi.org/10.1111/1467-968X.12310.
WordNet. 2010. WordNet 3.0. Available online at: http://wordnet.princeton.edu (accessed February 27, 2023).