Large language models often keep generating long chain-of-thought reasoning even when they already “know” the answer, burning tokens, adding latency, and occasionally wandering into confident nonsense, making it expensive to run. HALT-CoT tackles this with a simple inference-time rule: stop reasoning early once the model’s answer distribution becomes sufficiently sharp, meaning its uncertainty has dropped enough that additional steps are unlikely to improve the result.
Mechanically, after each reasoning step, HALT-CoT computes Shannon entropy over the model’s probabilities for the candidate answers, and halts once the entropy falls below a threshold 𝜃. The intuition is backed by the paper’s entropy dynamics analysis: on most correctly solved examples, uncertainty declines steadily across steps, so a threshold becomes a natural “we’re done here” signal rather than an arbitrary truncation.
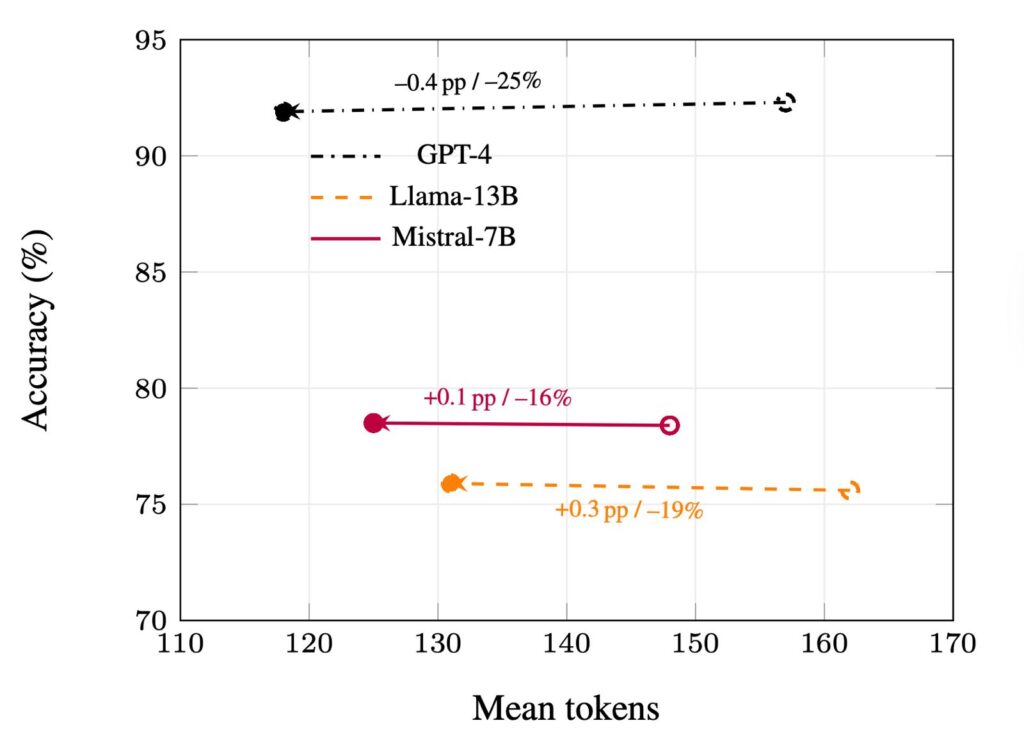
Across GSM8K, StrategyQA, and CommonsenseQA, HALT-CoT reports 15–30% fewer tokens while keeping accuracy within roughly ±0.4 percentage points of full chain-of-thought; one representative result is GPT-4 holding at about 92% on GSM8K while saving roughly 25% of decoding tokens. Its biggest practical win is that it’s training-free and model-agnostic no extra heads, no fine-tuning, just streamed token probabilities—making it a plug-and-play speedup for deployments where cost and latency actually matter. This work was accepted as a poster at the 4th MusIML workshop at ICML 2025.