Reasoning LLMs can improve in a way that’s strangely misleading: you post-train them on their own solved solutions, pass@1 rises, and it looks like clean progress yet some capabilities can slip backward at the same time. This pattern, often called self-improvement reversal, shows up when benchmark gains mask losses in robustness, breadth, or the range of solution strategies a model can reliably apply.
Most responses to reversal go in one of two directions. One is better measurement: build evaluation that can detect regressions hiding behind pass@1. The other is better supervision: shape reasoning more directly by rewarding correct intermediate steps (process supervision) rather than only the final answer. The paper behind this post takes a different route: it argues reversal isn’t just a reporting problem , it’s structural.
The key move is to stop treating “math reasoning” as one blob and instead view it as a landscape of concepts connected by prerequisites. In that view, post-training doesn’t improve reasoning uniformly; it redistributes capability across a concept graph. The losses tend to concentrate on the fringe: rare, prerequisite-heavy concepts that are easy to neglect because they appear less often in both training and evaluation.
To make that visible, the paper proposes an automated way to reconstruct structure from solutions inducing a prerequisite graph and a sparse problem-to-concept mapping—so you can track not just “did the model get the answer,” but which regions of the concept space improved and which degraded. It then proposes Fringe-Theorem Training (FTT): training-time interventions designed to preserve and recover those rare, deep skills while still improving overall accuracy so “getting better” stops meaning “getting narrower.”
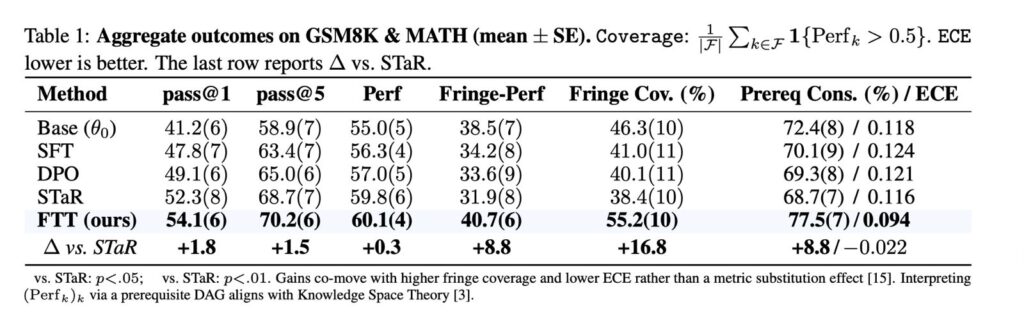
Standard post-training methods (SFT, DPO, STaR) boost pass@1 but don’t fix “long-tail” reasoning , those rare, prerequisite-heavy edge concepts. FTT improves both: it hits the best pass@1 (54.1) while jumping in fringe performance (40.7) and coverage (55.2%), solving more rare skills across a wider range. It also becomes better calibrated: prerequisite consistency rises to 77.5% and ECE drops to 0.094, aligning confidence with correctness. Accepted as a poster at NeurIPS 2025’s Efficient Reasoning workshop.